
Table of Contents
- 1. Introduction
- 2. A simple Pojo search
- 3. Fulltext, Facets and Score
- 4. Dynamic Fields
- 5. Special Sorting, Filters and Facets
- 6. An overall Example
- 7. Use Solr Remote Backend
- 8. Completable Search Server
- 9. Search Monitoring
- 10. Partial Updates
- 11. Nested Documents
- 12. Complex Fields
- 13. Contextualized fields
- 14. Search modifiers
1. Introduction
Vind (faɪnd) is a modular Java library which aims to lower the hurdle of integrating information discovery facilities in Java projects. It should help programmers to come to a good solution in an assessable amount of time, improve the maintainability of software projects, and simplify a centralized information discovery service management including monitoring and reporting.
In Vind we try to design an API which follows this 3 design principles:
1. Versatility: Vind will be used in many different projects, so it was an aim to keeping the dependency footprint small, which avoids version-clashes in the downstream projects.
2. Backend Agnostic: Wherever possible and feasible, the library has to abstracted from the basic search framework. This enabled us to change the backend without migrating application software.
3. Flat learning curve: It was an aim to keep the learning curve rather flat, so we tried to use Java built-in constructs whenever possible. Additionally we tried to follow the concept: easy things should be easy, complex things can (but does not have to) be complex.
The search lib is modular and currently implements the following layers:
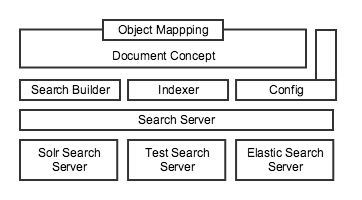
We built a short tutorial to give you a smooth entry to all the functions of the lib.
The runnable code for each step can be found under demo/demo-step{number}.
For a deeper dive in the API of Vind have a look at the Javadoc.
2. A simple Pojo search
Step one shows you, how quick and easy the search lib allows you to create a proper search on data items.
2.1. The dependency
The search lib is managed via maven/gradle repository. In our case we depend via maven dependency on the embedded solr server. For production we will change this dependency to a remote solr server later.
<dependency>
<groupId>com.rbmhtechnology.vind</groupId>
<artifactId>embedded-solr-server</artifactId>
<version>${vind.version}</version>
</dependency>
2.2. The pojo
Now we create a Pojo, which holds our data. To properly index it, we need at least an id-field. This field has to be annotated with @Id. All the other annotations that we introduce are optional.
@Id
private String id;
//the fulltext annotation means: 'use this for fulltext search'
@FullText
private String title;
//a field which is not annotated is just stored in the index
private ZonedDateTime created;
2.3. Create and Index
We instantiate a search server just by getting an instance. As mentioned before, it is an instance of an Embedded Solr Server. This server will loose all data when the program exit, so don’t use it for production.
//get an instance of a server (in this case a embedded solr server)
SearchServer server = SearchServer.getInstance();
//index 2 news items
server.indexBean(new NewsItem("1", "New Searchlib for Redbull needed", ZonedDateTime.now().minusMonths(3)));
server.indexBean(new NewsItem("2", "Redbull Searchlib available", ZonedDateTime.now()));
//don't forget to commit
server.commit();
2.4 Search and delete
Now we can retrieve the indexed documents via search. In addition we can delete existing News Items. After index and/or delete, the action has to be persisted via commit or is persisted automatically within 5 seconds.
//a first (empty) search, which should retrieve all News Items
BeanSearchResult<NewsItem> result = server.execute(Search.fulltext(), NewsItem.class);
//e voila, 2 news items are returned
assert result.getNumOfResults() == 2;
//delete an item
server.delete(i1);
server.commit();
//search again for all News Items
result = server.execute(Search.fulltext(), NewsItem.class);
//and we see, the item #1 is gone
assert result.getNumOfResults() == 1;
assert result.getResults().get(0).getId().equals("2");
3. Fulltext, Facets and Score
This step shows extended annotations and gives an overview on search.
3.1 Extended Annotations
We extend the Pojo from Step 1 with some more values. Depending on the role to play, the field is annotated accordingly.
//the field should be treated as english text
@FullText(language = Language.English)
private String title;
//we want to use this field for faceting and fulltext.
//additionally we want to boost the value for fulltext a bit (default is 1)
@FullText(language = Language.English, boost = 1.2f)
@Facet
private HashSet<String> category;
//this field is 'just' a facet field
@Facet
private String kind;
//we want to have a look at the search score (which is internally used for ranking)
//this field must be a float value and should not have a setter
@Score
private float score;
3.2 Search Building
No let’s try it out. You can see that the category field is used for fulltext search and it influences the score more than the title. The other searches in the examples show how to use sorting and filtering and how to generate facet results.
//this search should retrieve news items that should match the search term best
FulltextSearch search = Search.fulltext("redbull release");
BeanSearchResult<NewsItem> result = server.execute(search, NewsItem.class);
//now we want to have also the facets for category and kind.
//additionally we change the query
search.text("redbull");
search.facet("category","kind");
result = server.execute(search, NewsItem.class);
//new we define a search order based on the 'created ' field
search.sort(desc("created"));
result = server.execute(search, NewsItem.class);
//now we want to filter for all items with the kind 'blog'.
result = server.execute(Search.fulltext().filter(eq("kind","blog")), NewsItem.class);
3.3 Paging
Both the search and the result object supports paging.
//this search should retrieve news items
//we set the page to 1 and the pagesize to 1
FulltextSearch search = Search.fulltext();
search.page(1,1);
BeanPageResult<NewsItem> result = server.execute(search, NewsItem.class);
//lets log the results
System.out.println("--- Page 1 ---");
result.getResults().forEach(System.out::println);
System.out.println();
//the result itself supports paging, so we can loop the pages
while(result.hasNextPage()) {
result = result.nextPage();
System.out.println("--- Page " + result.getPage() + " ---");
result.getResults().forEach(System.out::println);
System.out.println();
}
3.4 Slicing
The search results can be also requested in the format of slices by specifying an offset and an slice size.
//declaration of the search object and its slice
final FulltextSearch searchAll = Search.fulltext().slice(1, 10);
//get the results contained in the slice
final BeanSearchResult<NewsItem> result = server.execute(search, NewsItem.class);
3.5 Suggestions
Suggestions suggest values based on free text. The suggestions also supports spellchecking
(which is used automatically in the backend). If the term has to be spellchecked
to get suggestions, the collated spellchecked term is included in the result. Otherwise this term is null.
SuggestionResult suggestions = server.execute(Search.suggest("c").field("category"), NewsItem.class);
//suggestions can be combined with filters
suggestion = server.execute(Search.suggest("c").field("title").filter(eq("kind","blog")), NewsItem.class));
//get spellchecked result
String spellcheckedQuery = suggestion.getSpellcheck();
Note: To query for suggestions on an specific field, it should previously have the suggest flag set to true.
4. Dynamic Fields
It is often useful to make item creation configurable on runtime. In this step we learn how to use a dynamic document configuration.
4.1 Dynamic Configuration
We create an DocumentFactoryBuilder with some fields (similar fields like the News Item in the former steps) which is used to build a immutable DocumentFactory.The fields are used later for both indexing and searching. IMPORTANT: In the current status the fieldnames ‘_type_’ and ‘_id_’ are reserved words, do not use them for custom fields.
private SingleValueFieldDescriptor.TextFieldDescriptor<String> title;
private SingleValueFieldDescriptor.DateFieldDescriptor<ZonedDateTime> created;
private MultiValueFieldDescriptor.TextFieldDescriptor<String> category;
private SingleValueFieldDescriptor.NumericFieldDescriptor<Integer> ranking;
private DocumentFactory newsItems;
public SearchService() {
//a simple fulltext field named 'title'
this.title = new FieldDescriptorBuilder()
.setFullText(true)
.buildTextField("title");
//a single value date field
this.created = new FieldDescriptorBuilder()
.buildDateField("created");
//a multivalue text field used for fulltext and facet.
//we also add a boost
this.category = new FieldDescriptorBuilder()
.setFacet(true)
.setFullText(true)
.setBoost(1.2f)
.buildMultivaluedTextField("category");
this.ranking = new FieldDescriptorBuilder()
.setFacet(true)
.buildNumericField("ranking", Integer.class);
//all fields are added to the document factory
newsItems = new DocumentFactoryBuilder("newsItem")
.addField(title, created, category, ranking)
.build();
}
4.2 Indexing dynamic documents
As simple pojos, dynamic documents can be added to the index and made visible by a commit.
server.index(item);
server.commit();
Additionally to that (as hard commit is a quite time consuming operation and not always necessary), we added a function that allows to index a document and guarantee, that is available by search within a certain ammount of milliseconds. Note, a hard commit is then not necessary (even if it is neccessary to persist the index to disc, you don’t have to take care, it’s been done automatically every 60 seconds). So, adding a document like this:
server.index(item, 2000);
guarantees, that the item can be found within 2 seconds.
5. Special Sorting, Filters and Facets
In this step we show which kind of special filters, facets and sorting the searchlib provides.
5.1 Special Sorting
//special sort filter allows to combine a date with scoring, so
//that best fitting and latest documents are ranked to top
search.sort(desc(scoredDate(created)));
//special sorting which gives results scored by distance to a
//given location. The distance is meassured based on the
//geoDistance defined for the search.
search.sort(desc(distance()));
Future Extensions: Support more sortings
5.2 Type-aware filters
When working with dynamic fields it is possible to create filters as shown in the previous example for annotated pojos, using helper methods from the Filter class and providing the field name and values, although it is recommended to create them making use of the type specific FieldDescriptor class helpers, which enforce type safe filter creation:
//Filter examples for datetime fields
search.filter(created.between(ZonedDateTime.now().minusDays(7), ZonedDateTime.now()));
search.filter(created.after(ZonedDateTime.now().minusDays(7)));
search.filter(created.before(ZonedDateTime.now()));
//Filter examples for numeric fields
search.filter(ranking.greaterThan(3));
search.filter(ranking.lesserThan(6));
search.filter(ranking.between(3,6));
//Filter examples for text fields
search.filter(title.terms("Zillertal", "Kalymnos", "Getu", "Teverga", "Yosemite", "Siurana"));
search.filter(title.equals("Climbing in Zillertal"));
search.filter(title.prefix("Climbing in"));
search.filter(title.isNotEmpty());
//Filter examples for Location fields
search.filter(locationSingle.withinBBox(new LatLng(10, 10), new LatLng(11, 1)));
search.filter(locationSingle.withinCircle(new LatLng(10, 10), 1));
search.filter(locationSingle.isEmpty());
A list of the type specific filters currently supported by the field descriptor syntax can be found here:
| NumericFieldDescriptor | DateFieldDescriptor | TextFieldDescriptor | LocationFieldDescriptor | All |
|---|---|---|---|---|
| between | between | equals | withinBBox | isEmpty |
| greaterThan | after | prefix | withinCircle | isNotEmpty |
| lesserThan | before | terms | ||
| terms | terms |
Future Extensions: Support more special filters
5.3 Special Field Facets
The library support several kind of facets. Facets have names, so they can be referenced in the result. Do not use the same name for more than one facet (they will be overwritten). For names only alphanumeric chars are supported.
//lets start with the range facet. It needs start, end and gap and is type aware.
search.facet(range("dates", created, ZonedDateTime.now().minus(Duration.ofDays(100)), ZonedDateTime.now(), Duration.ofDays(10)));
//query facets support the filters we already know from the queries, simple ones and complex
search.facet(query("middle", eq(category, 5L)));
search.facet(query("hotAndNew", and(category.between(7,10), created.after(ZonedDateTime.now().minus(Duration.ofDays(1))))))
//stats facet support statistics for facet field, like max, min, etc.
//it can be defined which stats should be returned, in this case count, sum and percentile
search.facet(stats("catStats", category).count().sum().percentiles(1,99,99.9));
//interval facets allows to perform faceting on a defined group of dates or numeric periodes; for each of those intervals it is needed to
//provide a name the start value, the end value, if it is open (includes the value) or closed (does not include the value) on the start
//and on the end. If not specified both sides are open.
search.facet(
interval("quality", marker,
Interval.numericInterval("low", 0L, 2L, true, false),
Interval.numericInterval("high", 3L, 4L)
)
);
//pivot facets allows facetting on facets
search.facet(pivot("catsCreated", category, created));
Every fulltext search created can set its own facet limit to specify the maximum number of results a facet can give back (default value is 10).
Search.fulltext().setFacetLimit(15).facet(title);
Although it is not the recommended usecase (normally facet resuts should be reduced to the most relevant terms), it is also possible to set the limit to ‘-1’ in order to get all the results in the response.
Note: Elasticsearch does not allow to get unlimited number of aggregations so instead Vind uses Integer.MAX_VALUE
It is also supported by the library the combination of pivots with the other kind of facets.
This is a work in progress
search.facet(pivot("catsNew", category, query("new",category.between(7,10))));
//if you want to use facets on the same level you can use lists
search.facet(pivot("catsNew", list(category, query("new",category.between(7,10)))));
6. An overall Example
This example uses the Spark micro framework and implements a search over guardian news articles. Be aware that this is just for demo purposes and therefor very limited. Just browse the code or run the application and have fun ;) To get it running an apiKey should be provided as parameter when running the java application.
6.1 API
HOST: http://localhost:4567/
- GET /index : Indexes 500 latest news
- GET /search : Simple search ** q: The query string ** filter: The category filter (combined by ‘or’) (multivalue)
- GET /news : Ranked by scored date ** q: The query string ** p: The page number ** sort: score | date | scoredate
- GET /suggest ** q: The query string
7. Use Solr Remote Backend
In this step we show how to use a Remote Solr Server as backend. Additionally we learn how change basic configurations of the search lib.
7.1 Dependencies
In order to use a Solr Remote Backend we have to switch the dependency to this.
<dependency>
<groupId>com.rbmhtechnology.vind</groupId>
<artifactId>remote-solr-server</artifactId>
<version>${vind.version}</version>
</dependency>
7.2 Configuration
Vind supports various types for configuration, which configuration by environment variables, by property file or/and by code interface. It comes with some basic configurations (like pagesize) that can be changed. The properties are overwritten following the ordering: Default Properties < Environment Variables < Property File.
Currently the following properties are supported:
| Key | Type | Description |
|---|---|---|
| server.collection | STRING | The solr collection name |
| server.host | STRING | The solr host or hostlist |
| server.provider | STRING | Fully qualified name of the solr provider |
| server.collection.autocreate | STRING | Collection is created if not existing (currently only in elastic) |
| server.connection.timeout | LONG | Connection timeout for remote server |
| server.so.timeout | LONG | Zookeeper client timeout |
| server.solr.cloud | BOOL | If remote solr runs in cloud mode |
| application.executor.threads | INT | Max. parallel threads for async connection |
| search.result.pagesize | INT | Result pagesize |
| search.result.showScore | BOOL | Include score in the result objects |
| search.result.facet.includeEmpty | BOOL | Include empty facets |
| search.result.facet.length | INT | Length for facet list |
| vind.properties.file | STRING | Path to property file |
Environment Properties
Environment Properties have a slightly different format. They start with the prefix VIND_, are uppercased and the dots are replaced underscored.
So e.g. server.solr.cloud turns to VIND_SERVER_SOLR_CLOUD.
Property File
For configuring e.g the remote host you have to place a file called searchlib.properties in the classpath which includes the host information.
//configure http client
server.host=http://localhost:8983/solr/searchindex
//configure zookeeper client
server.host=zkServerA:2181,zkServerB:2181,zkServerC:2181
server.solr.cloud=true
server.solr.collection=collection1
//change pagesize
search.result.pagesize=7
Code Interface
In addition to property file the static configuration interface allows also changes on runtime.
SearchConfiguration.set(SearchConfiguration.SERVER_SOLR_HOST, "http://example.org/solr/core");
If you cannot (or do not want to) change the dependency on different profiles you can have also 2 server dependency on classpath and select one by adding a configuration property. Currently 2 solr server provider (embedded and remote) are supported.
SearchConfiguration.set(SearchConfiguration.SERVER_SOLR_PROVIDER, "com.rbmhtechnology.vind.solr.EmbeddedSolrServerProvider");
SearchConfiguration.set(SearchConfiguration.SERVER_SOLR_PROVIDER, "com.rbmhtechnology.vind.solr.RemoteSolrServerProvider");
Attention: If you want to connect via zookeeper connection string, in addition to the host also the collection has to set.
SearchConfiguration.set(SearchConfiguration.SERVER_SOLR_PROVIDER, "com.rbmhtechnology.vind.solr.RemoteSolrServerProvider");
SearchConfiguration.set(SearchConfiguration.SERVER_SOLR_CLOUD, true);
SearchConfiguration.set(SearchConfiguration.SERVER_SOLR_HOST, "zkServerA:2181,zkServerB:2181,zkServerC:2181");
SearchConfiguration.set(SearchConfiguration.SERVER_SOLR_COLLECTION, "collection1");
HINT
If you want to test things with a standalone Solr Server we created a small script that helps you with that. The script is located in the main directory of the project. Usage:
./solr_remote.sh startdownloads solr (if necessary), configures the server and starts it./solr_remote.sh stopstops the running server
** Vind Solr backend with Docker
We created a Docker image redlinkgmbh/vind-solr-server which even simplifies the setup of a Solr backend for Vind. The image is hosted on Dockerhub. There you can find different versions, whereby the version number is aligned to the Vind release version. You can easily start a Vind Solr backend like this:
docker run -p 8983:8983 redlinkgmbh/vind-solr-server:1.3.0
This will start the server including the vind core. The configuration for the host is:
server.host=http://localhost:8983/solr/vind
8. Completable Search Server
In some cases a non-blocking search server is useful. the Completable Search Server uses Java CompletableFuture
and is implemented as a wrapper arround the existing search server. It can be instantiated
with an Executor or uses (by default) a FixedThreadPool with 16 threads. This number is configurable via
SearchConfiguration parameter application.executor.threads.
CompletableSearchServer server = new CompletableSearchServer(SearchServer.getInstance());
CompletableFuture<SearchResult> resultFuture = server.executeAsync(Search.fulltext(),factory);
9. Search Monitoring
Information about the activity of the users and how the tool performs is, for any information discovery system, of
mayor relevance in order to improve the behavior, provide more accurate results and track the possible errors. To
accomplish this easily, Vind provides a wrapper of the classic SearchServer, called MonitoringSearchServer,
which addresses this issue by recording full-text and suggestion searches.
Vind monitoring is divided in three main parts: API, writers and analysis. The API is meant to provide the basics
for custom implementations, the data model for the entries and the main MonitoringSearchServer class.
<dependency>
<groupId>com.rbmhtechnology.vind</groupId>
<artifactId>monitoring-api</artifactId>
<version>1.1.0</version>
</dependency>
While the writers module provide generic monitoring format writers, currently implementing a Log and an ElasticSearch writers.
<dependency>
<groupId>com.rbmhtechnology.vind</groupId>
<artifactId>elastic-writer</artifactId>
<version>1.1.0</version>
</dependency>
<dependency>
<groupId>com.rbmhtechnology.vind</groupId>
<artifactId>log-writer</artifactId>
<version>1.1.0</version>
</dependency>
Finally, the anlysis module is meant to provide pre-defined search analyzers aiming to extract relevant information out of the monitoring entries. At the moment, just a basic reporting analyzer is implemented generating statistical reports on search usage.
<dependency>
<groupId>com.rbmhtechnology.vind</groupId>
<artifactId>monitoring-analysis</artifactId>
<version>1.1.0</version>
</dependency>
9.1 The monitoring writers
Before having an instance of our MonitoringServer, a previous step is to choose a monitoring writer which behavior fits
the use case. Monitoring writers are meant to record the search executions in the desired format/storage(file, DB,…).
There are two default available writers included in monitoring-writers module: an Elastic Search writer and a Log writer.
It is also possible to implement custom writers, which should extend the abstract class com.rbmhtechnology.vind.monitoring.logger.MonitoringWriter,
provided in the monitoring-api artifact.
In this example we will use a simple testing MonitoringWriter which stores the entry logs in a list.
public class SimpleMonitoringWriter extends MonitoringWriter {
public final List<Log> logs = new ArrayList<>();
@Override
public void log(Log log) {
logs.add(log);
}
}
Note: This writer obviously has memory issues, do no use it as it is in a real use case.
9.1.1 Log writer
Based on the facade provided by Simple Logging Facade for Java (SLF4J), this implementation of the MonitoringWriter records
the monitoring entries serialized as Json using the, provided by the end user, logging framework.
<dependency>
<groupId>com.rbmhtechnology.vind</groupId>
<artifactId>log-writer</artifactId>
<version>1.1.0</version>
</dependency>
9.1.2 ElasticSearch writer
The monitoring entries are stored as Json in an ElasticSearch instance provided by the end user.
<dependency>
<groupId>com.rbmhtechnology.vind</groupId>
<artifactId>elastic-writer</artifactId>
<version>1.1.0</version>
</dependency>
9.2 The Monitoring server
The MonitoringSearchServer is a wrapper over SearchServer and can be used with any Vind backend. It
allows to set sessions so the entries can be identified in a later analysis process.
final Session session = new UserSession("213", "jdoe", "John Doe");
final MonitoringSearchServer monitoringServer = new MonitoringSearchServer(server, session);
//it can be used as a classic SearchServer
monitoringServer.execute(Search.fulltext(),factory);
To enrich the monitoring entries, it is also possible to instantiate the MonitoringServer providing more info about the
application which is performing the search and the current session.
//describe your application
final Application myApp = new InterfaceApplication("myAppName", "version-0.1.0",new Interface("myInterface", "version-0.0.1"));
//instantiate a session object
final Session currentSession = new UserSession("sessionID", new User("userName", "userID", "user.contact@example.org"));
//Get an instance of your report writer
final ReportWriter writer = ReportWriter.getInstance();
//get an instance of the monitoring server
final SearchServer monitoringServer = new MonitoringSearchServer(SearchServer.getInstance(), myApp, currentSession, writer);
Note: If no configuration is provided for the application the ReportingSearchServer will try to load from the Vind configuration the property ‘search.monitoring.application.id’. If it does not exist an exception will be thrown.
Additionally, it is possible to add custom information to the entries in two different ways:
- by setting general metadata in the
MonitoringServer, added to all activity record created by this server. - by setting action specific metadata, just recorded for the current search execution.
//get an instance of the monitoring server
final MonitoringSearchServer monitoringServer = new MonitoringSearchServer(SearchServer.getInstance(), myApp, currentSession, writer);
// Add a custom metadata entry which is applied to all the entries from this server.
monitoringServer.addMetadata("Module", "demo1-module");
final HashMap<String, Object> specificMetadata = new HashMap<>();
specificMetadata.put("Action", "demo2-specific-action")
//Add a custom metadata property for this specific search entry.
monitoringServer.execute(Search.fulltext(),factory, metadata);
9.3 The monitoring entry
A sample of a monitoring entry serialized as Json is displayed below:
{
"metadata": {
"module": "demo-2"
},
"type": "fulltext",
"application": {
"name": "Application name",
"version": "0.0.0",
"id": "Application name - 0.0.0",
"interface": {
"name": "test-interface",
"version": "0.0.0"
}
},
"session": {
"sessionId": "user 3",
"user": {
"name": "user 3",
"id": "user-ID-3",
"contact": null
}
},
"timeStamp": "2018-03-15T13:14:14.141+01:00",
"request": {
"query": "*",
"filter": {
"type": "TermFilter",
"field": "kind",
"term": "blog",
"scope": "Facet"
},
"facets": [
{
"type": "TermFacet",
"scope": "Facet",
"field": "kind"
},
{
"type": "TermFacet",
"scope": "Facet",
"field": "category"
}
],
"rawQuery": "q=*&fl=*,score&qf=dynamic_single_none_kind^1.0+dynamic_single_en_title^1.0+dynamic_multi_en_category^1.2&defType=edismax&fq=_type_:NewsItem&fq=dynamic_single_facet_string_kind:\"blog\"&start=0&rows=10"
},
"response": {
"num_of_results": 1,
"query_time": 2,
"elapsed_time": 3,
"vind_time": 5
},
"sorting": [
{
"type": "SimpleSort",
"field": "created",
"direction": "Desc"
}
],
"paging": {
"index": 1,
"size": 10,
"type": "page"
}
}
9.4 Reporting
Vind gives you a simple to use API for creating reports based on monitoring. The reports include:
- Usage overal
- Usage of searchs strings
- Usage of scoped filters (e.g. facets etc.)
The reports can be created on certain timerange:
//configure at least appId and connection (in this case elastic search)
final ElasticSearchReportConfiguration config = new ElasticSearchReportConfiguration()
.setApplicationId("myApp")
.setConnectionConfiguration(new ElasticSearchConnectionConfiguration(
"1.1.1.1",
"1920",
"logstash-2018.*"
));
//create service with config and timerange
ZonedDateTime to = ZonedDateTime.now();
ZonedDateTime from = to.minus(1, ChronoUnit.WEEKS);
ReportService service = new ElasticSearchReportService(config, from, to);
//create report and serialize as HTML
Report report = service.generateReport();
new HtmlReportWriter().write(report, "/tmp/myreport.html");
TODO: extend this description in a later release
10. Partial Updates
To be able to perform atomic updates in documents the DocumentFactory should be set as ‘updatable’ by seting the proper flag to true as described below:
DocumentFactory asset = new DocumentFactoryBuilder("asset")
.setUpdatable(true)
.addField(title, cat_multi, cat_single)
.build();
Once this pre-requisite are fulfilled partial updates are straight forward using field descriptors.
SingleValueFieldDescriptor<String> title = new FieldDescriptorBuilder()
.setFullText(true)
.buildTextField("title");
MultiValueFieldDescriptor.NumericFieldDescriptor<Long> cat_multi = new FieldDescriptorBuilder()
.setFacet(true)
.buildMultivaluedNumericField("category", Long.class);
SingleValueFieldDescriptor.NumericFieldDescriptor<Long> cat_single = new FieldDescriptorBuilder()
.setFacet(true)
.buildNumericField("category", Long.class);
server.execute(Search.update("123").set(title,"123").add(cat_multi,1L,2L).remove(cat_single));
11. Nested Documents
Nested documents are supported by allowing to add documents as child fields of other documents. It is a fixed restriction that the nested document type is not the same as the parent document, so each one has to have defined their own DocumentFactory with a unique name.
The nested documents are added to the parent document as described below:
SingleValueFieldDescriptor<String> title = new FieldDescriptorBuilder()
.setFullText(true)
.buildTextField("title");
SingleValueFieldDescriptor<String> color = new FieldDescriptorBuilder()
.setFullText(true)
.buildTextField("color");
DocumentFactory marker = new DocumentFactoryBuilder("marker")
.addField(title, color)
.build();
DocumentFactory asset = new DocumentFactoryBuilder("asset")
.addField(title, color)
.build();
Document a1 = asset.createDoc("A1")
.setValue(title,"A1")
.setValue(color,"blue");
Document a2 = asset.createDoc("A2")
.setValue(title, "A2")
.setValue(color,"red")
.addChild(marker.createDoc("C1")
.setValue(title, "C1")
.setValue(color,"blue")
);
After indexing and commit the parents, the nested document will be added to the index as any other document but keeping an internal relation with the parent. Therefore it is possible to perform search by types in both, parents or children documents.
server.execute(Search.fulltext("some"), asset); //search assets
server.execute(Search.fulltext("some"), marker); //search markers
Having nested documents allows to perform complex queries on them, excluding or including results based on matching children. If a fulltext search is not specified, the same query and filters used for the parent documents will be used for matching the child documents.
//Search for those assets with color blue in either the asset or the marker.
SearchResult orChildrenFilteredSearch = server.execute(
Search.fulltext()
.filter(Filter.eq(color, "blue"))
.orChildrenSearch(marker),
asset);
//Search for those assets with color blue in both the asset and the marker.
SearchResult andChildrenFilteredSearch = server.execute(
Search.fulltext()
.filter(Filter.eq(color, "blue"))
.andChildrenSearch(marker),
asset); //search in all markers
//First filter the assets with color blue or a marker with color red, then search those assets with
//a '1' in fulltext field or any marker.
SearchResult orChildrenCustomSearch = server.execute(
Search.fulltext("1")
.filter(Filter.eq(color, "blue"))
.orChildrenSearch(
Search.fulltext()
.filter(Filter.eq(color, "red")),
marker),
asset); //search in all markers
12. Complex Fields
There are special situations in which having the same value for every scope (storing, fulltext search, filtering, faceting, suggesting or sorting) may not be enough for the project requirements. Think of the scenario of a taxonomy term, with a unique identifier for filtering, a label for storing, sorting or faceting, plus a a set of synonyms for full text search and suggestions. Such a situation cannot be covered by the basic field descriptors, and to fill in that gap complex field descriptors where created.
A complex field descriptor is a field storing a simplified view of a java class, and which it is declared by providing the methods to calculate the values for each of the specific scopes desired.
SingleValuedComplexField.NumericComplexField<Taxonomy,Integer,String> numericComplexField = new ComplexFieldDescriptorBuilder<Taxonomy,Integer,String>()
.setFacet(true, tx -> Arrays.asList(tx.getId()))
.setFullText(true, tx -> Arrays.asList(tx.getTerm()))
.setSuggest(true, tx -> Arrays.asList(tx.getLabel()))
.buildNumericComplexField("numberFacetTaxonomy", Taxonomy.class, Integer.class, String.class);
MultiValuedComplexField.TextComplexField<Taxonomy,String,String> multiComplexField = new ComplexFieldDescriptorBuilder<Taxonomy,String,String>()
.setFacet(true, tx -> Arrays.asList(tx.getLabel()))
.setSuggest(true, tx -> Arrays.asList(tx.getLabel()))
.setStored(true, tx -> tx.getTerm())
.buildMultivaluedTextComplexField("multiTextTaxonomy", Taxonomy.class, String.class, String.class);
The complex field definition has 3 types to be specified, the first one is the complex java class to be stored, in the previous example Taxonomy. The second one should be the returning type of the facet function, Integer in the example as the Id would be the value used for the faceting. Finally a 3rd type for the sort scope. Suggestion and fulltext scope will be always expecting a String type return function.
Note: Facet, FullText and Suggest are design to be always multivalued so the functions providing their values should return an array of the expected type.
12.1 Advance Filter
A new scope has been added to the complex filter, which only purpose is to do filtering. This field values should have the same type defined for faceting and it is always multivalued.
SingleValuedComplexField.NumericComplexField<Taxonomy,Integer,String> numericComplexField = new ComplexFieldDescriptorBuilder<Taxonomy,Integer,String>()
.setAdvanceFilter(true, tx -> Arrays.asList(tx.getTerm()))
.buildNumericComplexField("numberFacetTaxonomy", Taxonomy.class, Integer.class, String.class);
12.2 Scoped filters
As with the complex fields it is possible to have different values for different scopes, the filters support the option to specify the scope in which they apply:
- Scope.Facet
- Scope.Filter
- Scope.Suggest
server.execute(Search.fulltext().filter(textComplexField.equals("uno",Scope.Filter)), assets);
Note: The default scope is facet.
13. Contextualized fields
Searchlib supports the definition of document fields which can have different values for different contexts, allowing to get
final Document d1 = assets.createDoc("1")
.setValue(numberField, 0f)
.setContextualizedValue(numberField, "privateContext", 24f)
.setContextualizedValue(numberField, "singleContext", 3f)
.setValue(entityID, "123")
.setValue(dateField, new Date());
The search context can be set when creating the search object by the method modifier context(“contextname”):
final FulltextSearch searchAll = Search.fulltext().context("numberContext").filter(and(eq(entityID, "123"), eq(numberField,24f))).facet(entityID);
Those values which belong to a different context thant the one defined will not be in the search result.
final SearchResult searchResult = server.execute(searchAll, assets);
searchResult.getResults().get(0).getContextualizedValue(numberField, "numberContext"));
14. Search modifiers
In this step the existing search modifiers are be described.
14.1 Strict search
By default every search is a strict search which means that, having nested documents, no filters or search can be define for children using fields belonging just to the parent document factory.
By setting the search flag strict to false nested document search will extend the defined filters or search queries in parent document fields to the children as if they had inherited the field itself.
FulltextSearch search = Search.fulltext().setStrict(false).filter(eq(parent_value, "blue")).andChildrenSearch(child);
The previous example will return all the parent documents which field parent_value has value “blue”.
14.2 Geo distance
The distance to the specified LatLong point will be calculated and added to the search result for e Every document with the field locationgSingle.
Search.fulltext().geoDistance(locationSingle,new LatLng(5,5))